i4Q Manufacturing Line Reconfiguration Toolkit¶
General Description¶
i4QLRT is a collection of optimisation micro-services that use simulation to evaluate different possible scenarios and propose changes in the configuration parameters of the manufacturing line to achieve improved quality targets. i4QLRT AI learning algorithms develop strategies for machine parameters calibration, line setup and line reconfiguration.
The objective of Manufacturing Line Reconfiguration Toolkit is to increase productivity and reduce the efforts for manufacturing line reconfiguration through AI. This tool consists of a set of analytical components (e.g., optimisation algorithms, machine learning models) to solve known optimisation problems in the manufacturing process quality domain, finding the optimal configuration for the modules and parameters of the manufacturing line. Fine-tune the configuration parameters of machines along the line to improve quality standards or improve the manufacturing line set-up time are some examples of the problems that the i4QLRT solves for manufacturing companies.
Features¶
It provides the possibility to deploy algorithms at the edge of the network, via distributable files.
Provides informations necessary to understand the use, characteristics and needs of the algorithm.
Offers the ability to instantiate an algorithm.
Allows algorithms to be run and solved at the edge of the network, obtaining information directly from the production line. In this way, the algorithms can optimise the production line automatically.
ScreenShots¶

Comercial Information¶
Authors¶
Partner |
Role |
Website |
Logo |
|---|---|---|---|
UPV |
Leader |
||
IKERLAN |
Vice-Leader |

|
|
EXOS |
Participant |

|
License¶
The licence is per subscription of 150€ per month.
Pricing¶
Subject |
Value |
|---|---|
Installation |
60€ (5-20 hours) |
Customisation |
60€ (10-50 hours) |
Training |
60€ (8-24 hours) |
Associated i4Q Solutions¶
Required¶
Can operate without the need for another i4Q solution
Optional¶
System Requirements¶
- docker requirements:
4 GB Ram
64-bit operating system
Hardware virtualisation support
API Specification¶
Resource |
POST |
GET |
PUT |
DELETE |
|---|---|---|---|---|
/metadata |
Not Supported |
Provides a description of the Algorithm, including a description of inputs and outputs |
Not Supported |
Not Supported |
/result |
Run the algorithm with the current input and output configuration |
Not Supported |
Not Supported |
Not Supported |
/subscription |
Supported |
Supported |
Supported |
Supported |
/instanciate |
Supported |
Supported |
Supported |
Supported |
Installation Guidelines¶
Resource |
Location |
|---|---|
Code |
|
Release (v 0.1.0) |
Installation¶
This component is designed to be used by both docker and kubernetes.
Docker environment:
For docker-based installation it can be achieved by running a Docker-compose command. For each data processing algorithm, a separate Docker-compose file is provided. For example, the following command starts an instance of the component
cd orchestration
docker-compose -f docker-compose.mjanaive.yaml up --build --remove-orphans
Kubernetes environment:
To deploy it on Kubernetes, helm files are prepared, which can be launched from commands. For example, the following command starts an instance of the Machine-Job Assignment Naive Algorithm.
cd charts
cd mjanaive
helm install mjanaive ./ --namespace mjanaive --set defaultSettings.registrySecret=i4q-lrt-mjanaive,privateRegistry.registryUrl=registry.gitlab.com,privateRegistry.registryUser=user.gitlab,privateRegistry.registryPasswd=my-password-or-token
User Manual¶
How to use¶
The API functionality can easily be tested using the Swagger UI, which is currently deployed with the Flask application.
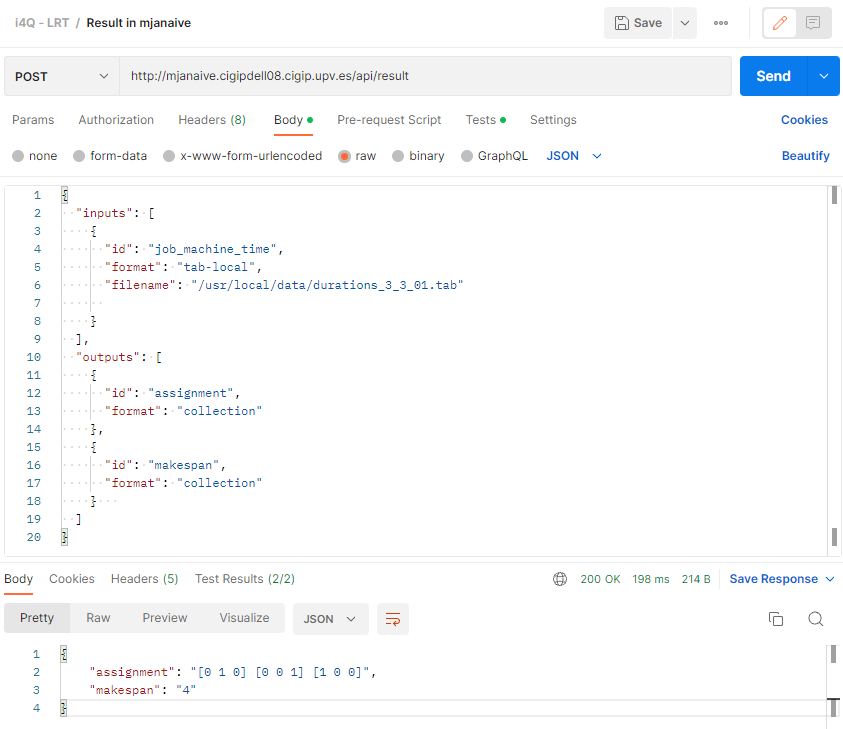
The JSON body of the POST request to /result consists of three keys (‘inputs’, ‘outputs’ and ‘module_parameters’) which are lists of JSON objects with the following structure:
{
{
"inputs": [{
"id": "string",
"format": "string",
"*format*": {
//DEPENDING FORMAT STRUCTURE
}
}],
"module_parameters": [{
"id": "string",
"format": "string",
}],
"outputs": [{
"id": "string",
"format": "string",
"*format*": {
//DEPENDING FORMAT STRUCTURE
}
}]
}
}
id: Identifier of the input or output parameter, specified in the metadata of the component
For input/module_parameters: The name of the argument of the “compute” function (of computeUnit) to which the input should be passed
For output: The computeUnit returns the results as a python dictionary. The “id” refers to the key of the returned dictionary
format: Specifies the format of the input or output data parameter. The values of this key can be “filename”, “mongo-collection”, “collection”, “mqtt”
depending on the value of key “format”, (in the schema above), the key <format> should be replaced with one of the following keys:
filename: (Optional) For file/csv inputs, specifies the file name of the file containing the input data. Currently the files must be available in a Docker-volume made available using Docker-compose. Later the CSV files will be in the Storage component
mongo-collection: (Optional) For database/mongo inputs. This config is a JSON that specifies the ‘mongo_uri’ and the ‘query’ details:
For input:
mongo_uri: Used to connect to the mongoDB
(Optional) operation: Either ‘find’ or ‘aggregate’, defines which operation is used to retrieve the data. Default is ‘find’ if not present
collection_name: The name of the mongo collection on which the operation is applied
For output:
mongo_uri: Used to connect to the mongoDB
collection_name: The name of the mongo collection under which the data is stored. Note: The data is stored using mongoDBs ‘insert_many’
collection: (Optional) For collection data, contains the collection (data) in json format
mqtt: (Optional) For message bus data. This config is a JSON that contains the message bus topic to subscribe/publish to as well as an optional ring buffer length:
For input:
topic: The name of message bus topic
(Optional) historyLength: for ring buffer (which stores the stream data) length. Default is 1
For output:
topic: The name of message bus topic
kafka: (Optional) For broker message kafka. This config is a JSON that contains the message broker topic, the server, group identification and histry limit.
For input:
topic: The name of message broker topic.
limit: for ring buffer length.
server: The address of kafka’s server.
group: The group maintains its offset per topic partition.
For output:
topic: The name of the message broker topic where you want to dump the new information.
server: The address of kafka’s server.
group: The group maintains its offset per topic partition.