i4Q Data Repository (i4QDR)¶
General Description¶
The i4Q Data Repository (i4QDR) is a distributed storage system that will oversee receiving, storing, and serving the data in an appropriate way to other solutions. This solution is suitable to support and enhance a high degree of digitization in companies with most manufacturing devices acting as sensors or actuators and generating vast amounts of data.
The i4Q Data Repository (i4QDR) is aimed at providing, in a centralised fashion, the functionality related to the storage of data in the whole i4Q system. Indeed, the i4QDR is involved in all the pilots and is expected to interoperate with a large subset of the i4Q solutions.
The i4Q Data Repository includes a collection of toolkits to configure, bootstrap and manage a number of tools and technologies related to the storage and management of data, supporting different usage scenarios.
The i4Q Data Repository supports the following data storage technologies:
Cassandra, a wide-column NoSQL distributed database server, appropriate for managing massive amounts of data.
MariaDB, a SQL relational database server.
MinIO, which offers a high-performance, S3 compatible object storage. It is used to store files and is compatible with any public cloud.
MongoDB, a JSON document-oriented database server.
MySQL, a SQL relational database server, very similar to MariaDB.
Neo4J, a graph database server that allows storing data relationships.
PostgreSQL, a SQL relational database server.
Redis, an in-memory data structure store, used as a distributed, in-memory key–value database, cache, and message broker, with optional durability.
TimeScaleDB, a time-series SQL database which is an extension of PostgreSQL.
The i4Q Data Repository offers a variety of configurations or scenarios of the supported data storage technologies. These scenarios can be seen as different ways of deploying the tools to meet some requirements related to aspects such as performance or security. More specifically, the following four scenarios have been defined:
Single server (SS) scenario, which offers the tool in its most basic version. It leverages a single instance of the tool, ready to be used. It is worth noting that such single instances do not consider any security issue beyond its default configuration. Thus, an “SS” scenario is only recommended for the development tasks of a pilot or solution.
Single server with TLS security (SS+Sec) scenario, that offers the tool with a security configuration based on the use of TLS (with x509 certificates). This scenario is suitable for production settings in which a single instance of the tool suffices to provide a secure and stable service.
High availability (HA) scenario, which offers the tool in a high availability mode. This typically involves defining some cluster or replica set environment, composed by a number of instances of the tool that work in a cooperative mode (for instance, a cluster of replicas of a database server). Again, these instances do not offer any security mechanism beyond those that are offered by default and are, thus, only recommended for development purposes.
High availability with TLS security (HA+Sec) scenario, which extends the “HA” scenario with a security configuration based on the use of TLS. This is the recommend option to offer a secure, fault-tolerant, highly available service.
The scenarios implemented for each technology depend on the needs from other tools and pilots. The table below shows which scenarios have been implemented for each technology.
Storage Technology |
Scenarios |
|---|---|
Cassandra |
SS |
MariaDB |
SS, SS+Sec |
MinIO |
SS, SS+Sec |
MongoDB |
SS, SS+Sec, HA, HA+Sec |
MySQL |
SS, SS+Sec |
Neo4J |
SS, SS+Sec |
PostgreSQL |
SS, SS+Sec |
Redis |
SS, SS+Sec |
TimeScaleDB |
SS, SS+Sec |
The i4Q Data Repository allows the user to select which storage technologies and scenarios have to be deployed (see below for more information). For each one of the technologies and scenarios selected, one or more Docker containers containing an instance of the corresponding storage technology are built and launched. In the case of the “Single Server” scenario, only one instance is deployed, whereas more than one are deployed in the case of the “High Availability” scenario. Note, however, that other containers for other tools and purposes may be built and run in some cases. For instance, in the case of MongoDB a container to run an instance of Mongo Express, a web-based interface to administrate MongoDB instances, is also deployed.
This solution involves also the deployment of Trino to implement a layer on top of the toolkits implemented for each storage technology. The purpose of this layer is two-fold. On the one hand, to improve the interoperability of the i4QDR with other i4Q solutions and, on the other hand, to facilitate the support to other storage technologies in the future, if necessary. Trino is a highly parallel and distributed ANSI SQL-compliant open-source query engine that offers a relational-like view of different data storage tools. Moreover, Trino allows the execution of federated queries, which means that several databases of different types (relational, object storage, streaming or NoSQL, etc.) can be accessed within the same query.
Finally, the i4Q DR solution includes a graphical user interface (GUI) to allow for a better simplified user experience, especially aimed at facilitating the deployment of the solution. The i4QDR GUI has been implemented using Vue.js , a JavaScript Framework for building web user interfaces.
The figure below shows an overview of the i4Q Data Repository architecture.
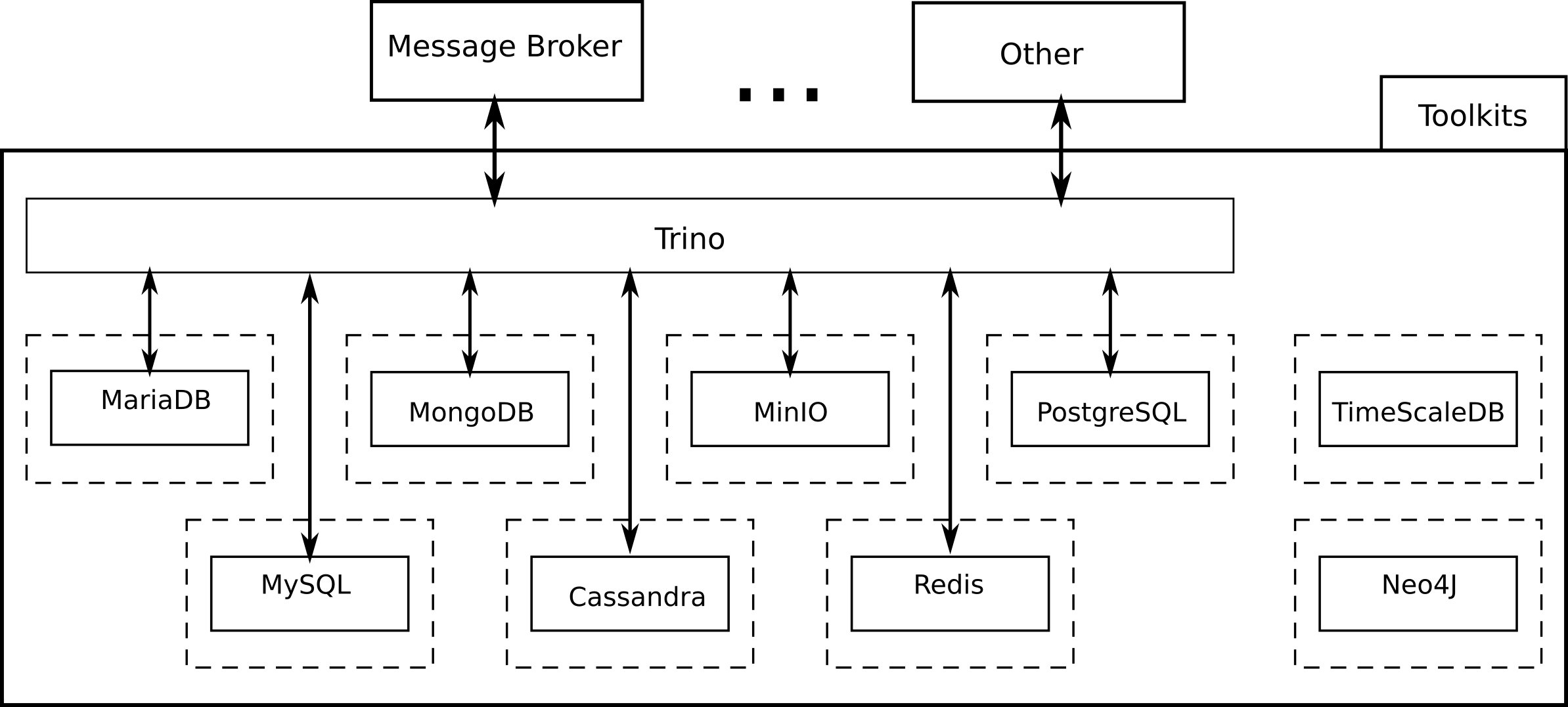
Architectural overview of i4Q Data Repository¶
Features¶
The features of the i4QDR are as follows:
An access control mechanism: to ensure that only authorised entities have access to the data and the related tools. Users with the appropriate permissions will be able to configure this access control, to grant access to the allowed entities.
Tools and technologies to manage structured data: this feature will be offered by means of DBMSs that may be relational SQL-based, document (e.g., JSON-based), general NoSQL tools, etc.
Tools and technologies to manage blobs: this feature will be offered through tools that offer support for blobs like some general-purpose DBMSs or even specific ones (e.g., Minio).
Efficient mechanisms to query the stored data and retrieve the results of such queries: for both structured data and blobs.
Mechanisms to import/export data to/from the i4QDR: o ease the interoperability of this solution with others.
Mechanisms to manage the data repository itself.
ScreenShots¶
Graphical User Interface¶
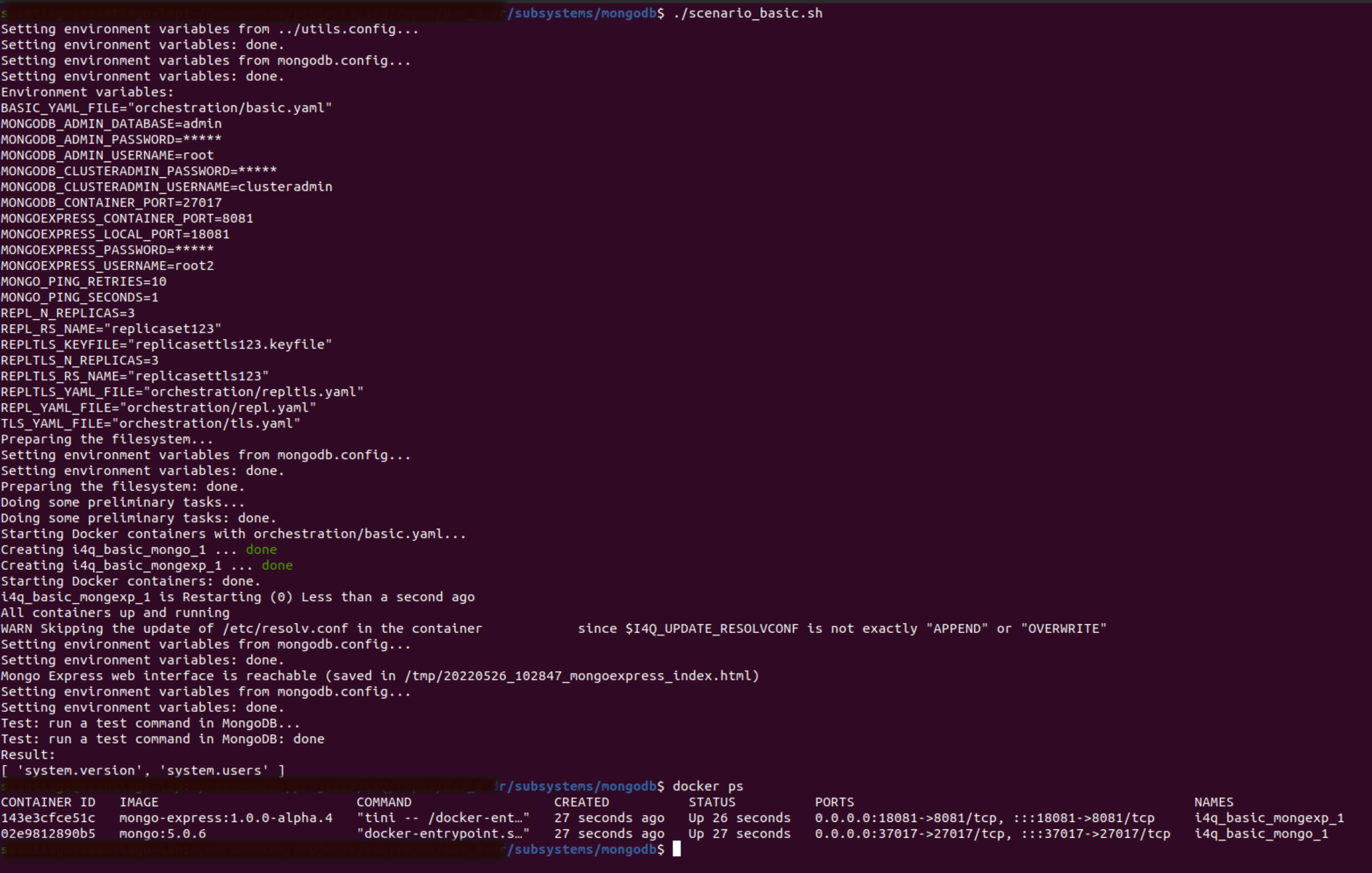
Bootstrapping single server scenario for MongoDB from console¶
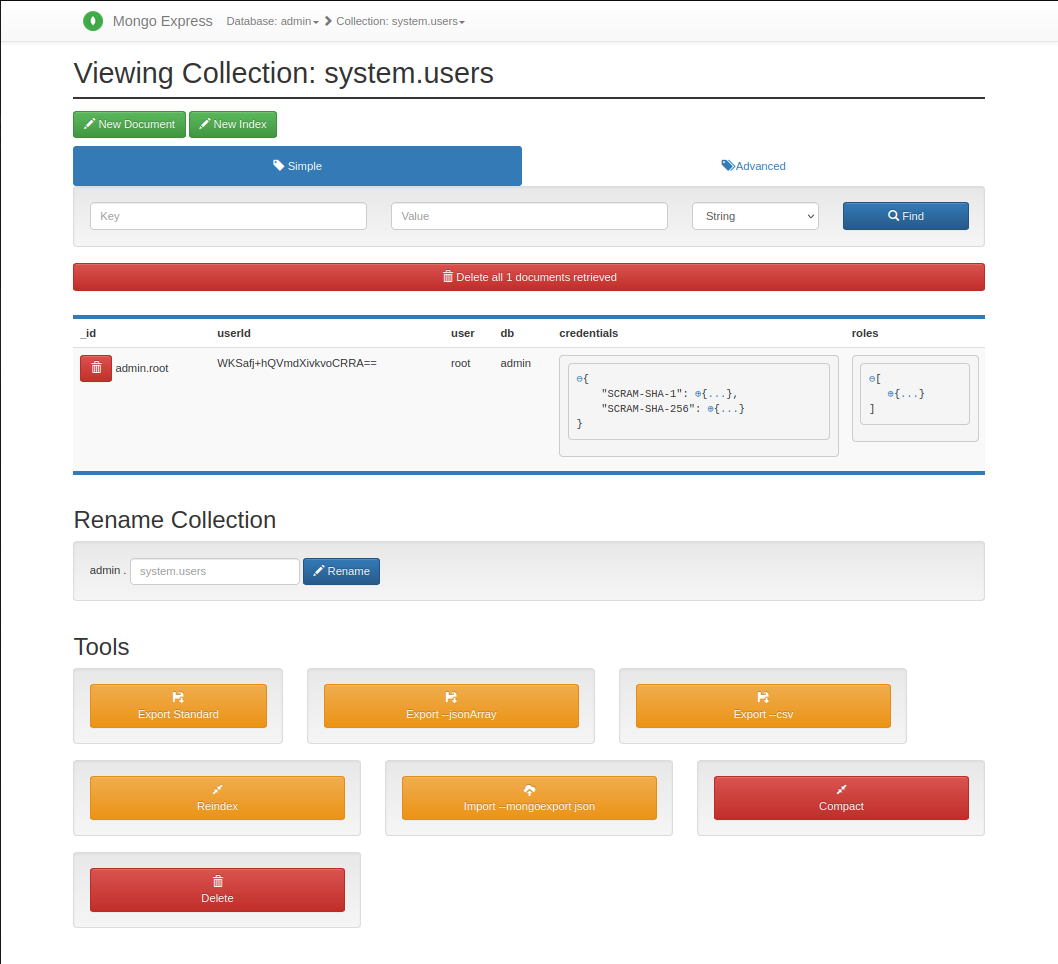
MongoExpress instance running after bootstrapping SS scenario for MongoDB¶
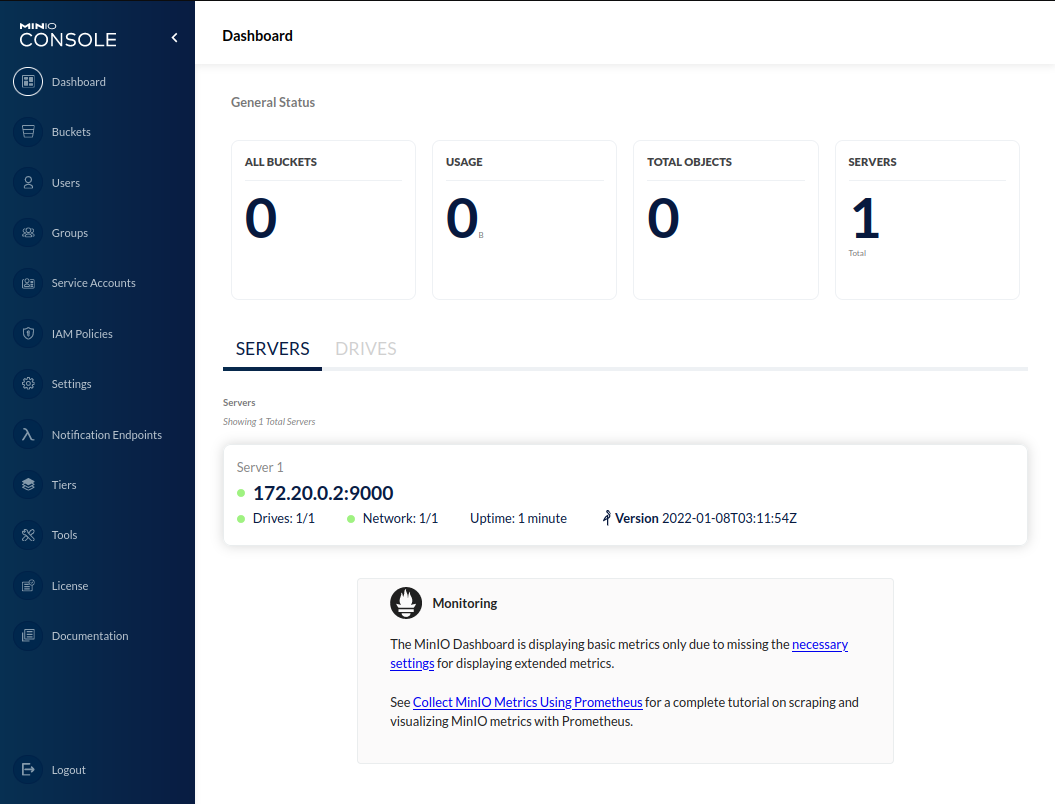
MinIO instance running after bootstrapping SS scenario¶
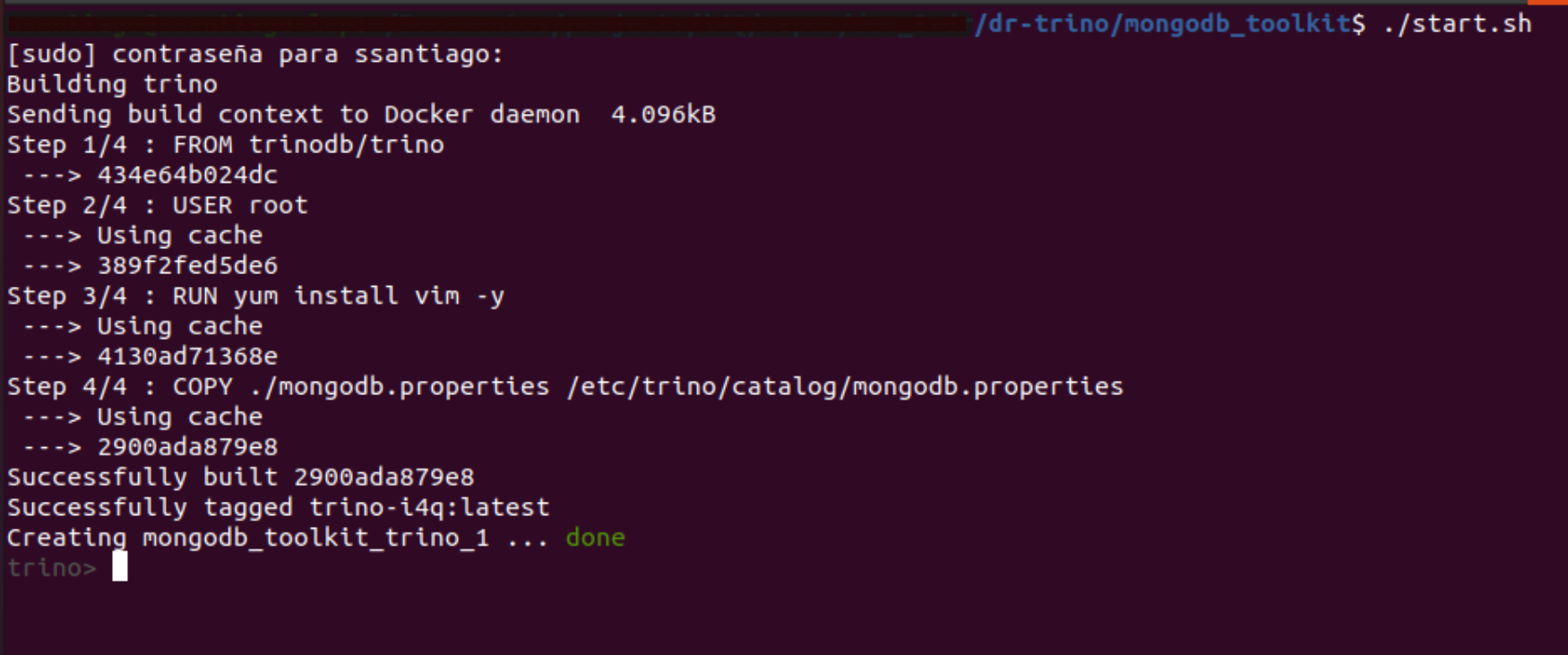
Bootstrapping of Trino with a MongoDB connector¶
Comercial Information¶
Authors¶
Company |
Website |
Logo |
|---|---|---|
ITI |

|
|
Uninova |

|
|
Engineering |

|
|
CERTH |

|
|
Knowledgebiz |

|
License¶
A free-software license
Pricing¶
Subject |
Value |
|---|---|
Payment Model |
One-off |
Price |
0 € |
Associated i4Q Solutions¶
Required¶
Currently, it can operate without the need for another i4Q solution. However, to deploy the Single Server and High Availability “with security” scenarios it is required the use of i4QSH solution to generate the corresponding SSL certificates.
Optional¶
None. However, the i4QDR is expected to be used with almost any other i4Q solution in the pilots, either to store data, or to allow the retrieval of previously stored data.
Furthermore, in several pilots, the i4Q DIT (i4Q Data Integration and TransformationServices) solution is used to pre-process data before storing it in i4QDR.
Finally, to communicate i4QDR with other i4Q solutions, the recommended approach is to use the i4Q Message Broker.
System Requirements and dependencies¶
- Docker requirements:
4 GB Ram
64-bit operating system
Hardware virtualisation support
Additionally, it requires the following dependencies to be already installed:
Bash, to run the scripts. They contain a few syntax details specific to Bash that may not work with other shells (Dash, csh, ksh, zsh, etc.). Any recent version will do.
Docker Engine and Docker Compose, to deploy and run containers. Any recent version accepting version 3.9 Docker Compose YAML files will do.
OpenSSL, to create test SSL artifacts (keys, certificates, etc.). Any recent version will do.
curl, to retrieve files required to build the Docker images.
jq, to manipulate JSON files. Any recent version will do. This is required by the toolkits for MinIO and MongoDB.
API Specification¶
Since Trino is expected to be deployed as a layer on top of the different toolkits, the plan is to use Trino REST API as a mechanism to interact with the i4QDR. This REST API offers the following endpoints:
Resource |
POST |
GET |
PUT |
DELETE |
|---|---|---|---|---|
/v1/statement |
runs the query string in the POST` body, and returns a JSON document containing the query results. If there are more results, the JSON document contains a nextUri URL attribute. |
Not Supported |
Not Supported |
Not Supported |
/nextUri` |
Not Supported |
Returns the next batch of query results |
Not Supported |
Terminates a running query |
Installation Guidelines¶
Resource |
Location |
|---|---|
Last release (v.0.2.0) |
|
Video |
First, make sure your system fulfils the requirements specified above.
Then, check the dependencies listed above are installed in your system.
Obtain the source code of the i4QDR solution. For instance, by cloning the repository of the i4QDR solution, available at https://gitlab.com/i4q/dr. Note that you may need to request access to it.
Follow the instructions explained in the “User Manual” section below.
User Manual¶
The i4Q Data Repository solution is deployed by running a launcher script (“run.sh”). This script allows to launch a number of scenarios of the available toolkits and an instance of Trino that can connect to them, as well.
The main actions performed by the script are these:
Prepare a Docker Compose .yaml file for Trino with content that depends on the data storage tools to be deployed.
Save a backup of the current Docker Compose .yaml file for Trino.
Launch a number of data storage tools (eg. MongoDB, MySQL, etc.).
Launch Trino.
The launcher script accepts different parameters and options to specify which storage technologies and scenarios must be deployed. The user of i4QDR can obtain the concrete command that needs to be executed in a console in two ways:
Using the i4QDR’s graphical user interface (GUI).
Manually writing the command, considering the different parameters and options of the launcher script.
The rest of this section is structured as follows:
Subsection “Deployment of the solution using the Graphical User Interface” explains how to use the i4QDR’s graphical user interface to obtain the concrete command that allows to deploy the i4QDR for the technologies and scenarios selected by the user.
Subsection “Deployment of i4QDR from the console” describes in detail the different parameters and options accepted by the launcher script. The information provided in this section allows the user to manually specify the command to deploy the i4QDR for the technologies and scenarios of her choice.
Subsection “Manual bootstrapping of toolkits’ scenarios (without deploying Trino)” explains how to bootstrap the i4QDR toolkits’s scenarios as independent components. This deployment option allows the user to bootstrap only a given storage technology for a specific scenario, without deploying Trino.
Subsection “Usage of toolkit-related and scenario-related functions” provides specific information regarding toolkit-specific functions. This information is aimed at providing a deeper insight on the implementation of the solution.
Deployment of the solution using the Graphical User Interface¶
The first step is to bootstrap the GUI. This can be done by running a the GUI launcher script (“runGUI”) with the following command:
$ ./runGUI.sh
Once the GUI has been bootstrapped, it is reachable at the URL: “http://localhost:8080”.
More specifically, the GUI developed for the i4QDR consists of three screens:
A “landing” screen “Home”, providing general information on the GUI and links to the other screens.
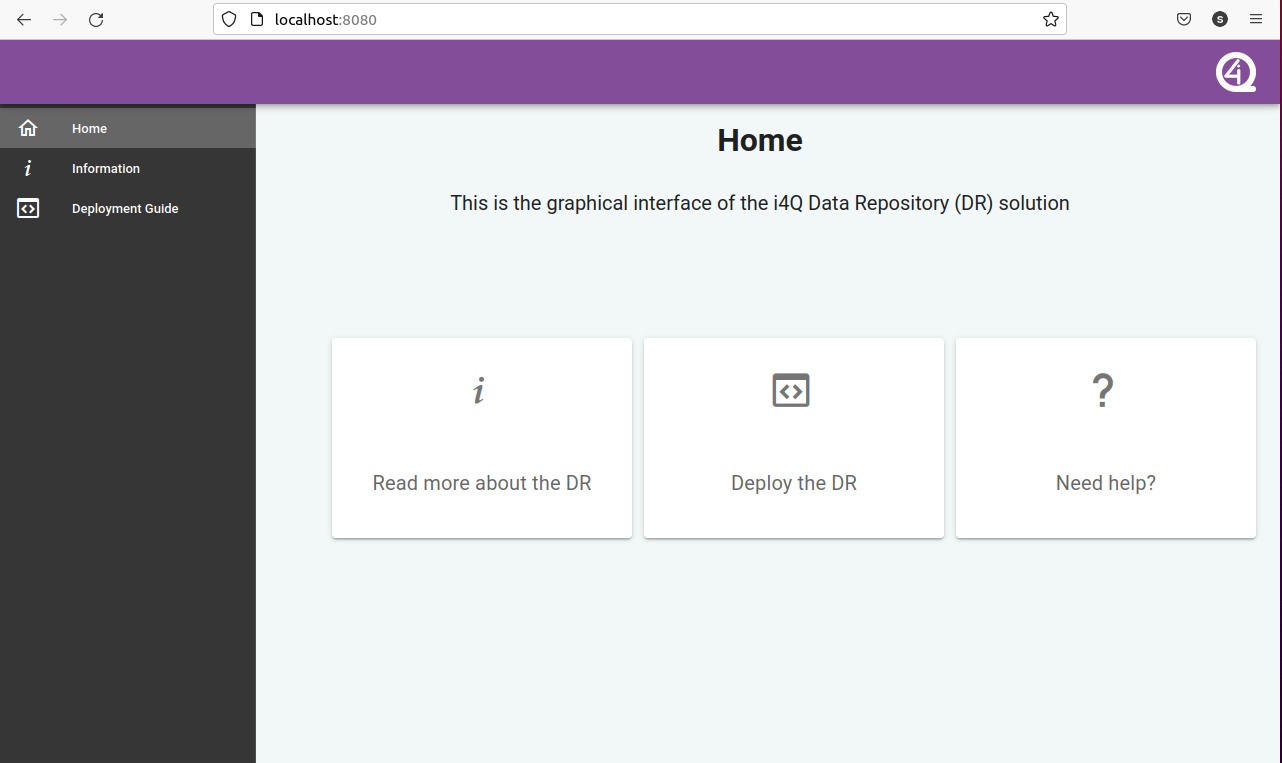
GUI - Screen “Home”¶
Screen “Information”, which explains the purpose of the i4QDR, and describes the storage technologies and scenarios supported, as shown in the figure below.
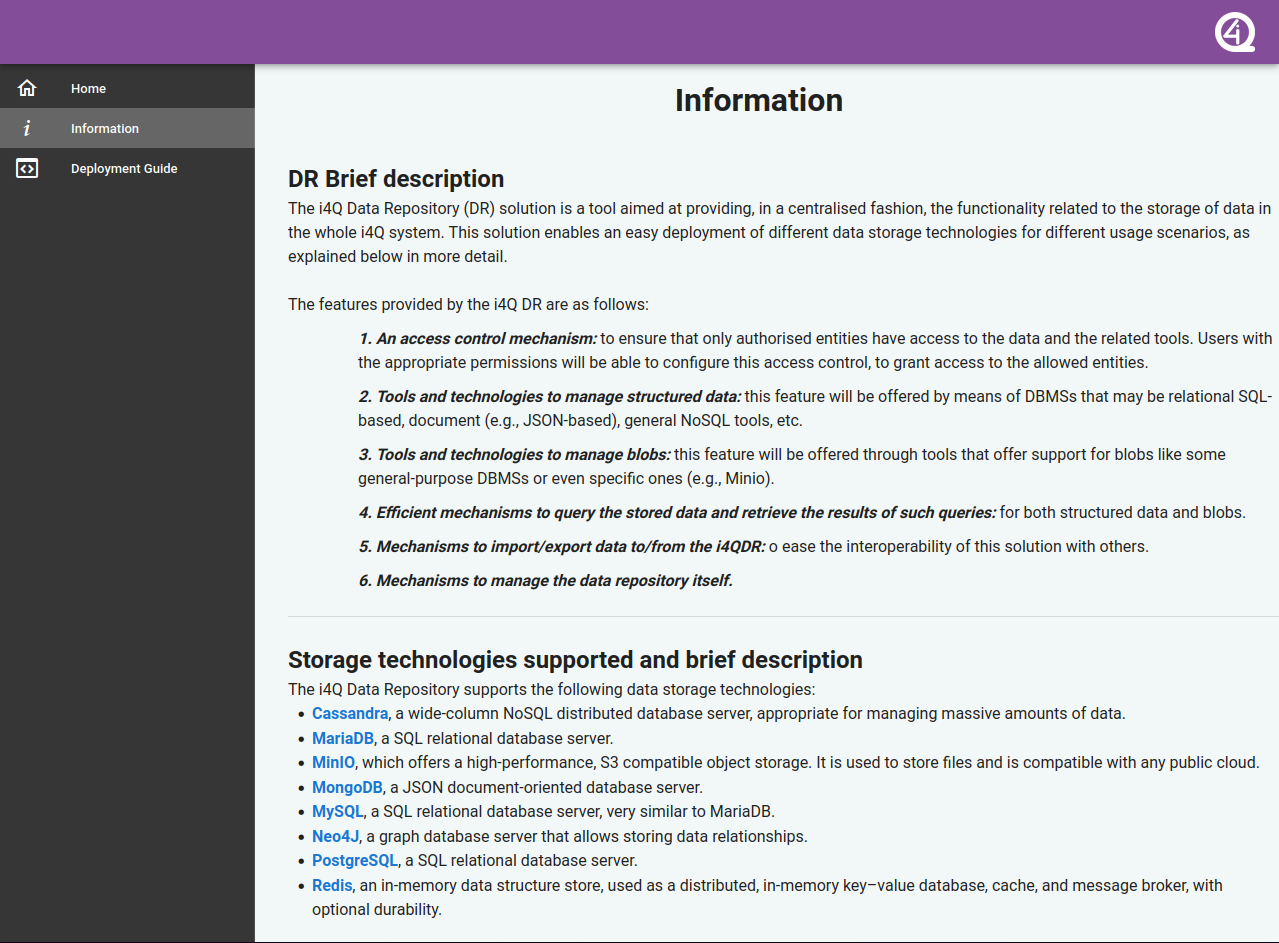
GUI - Screen “Information”¶
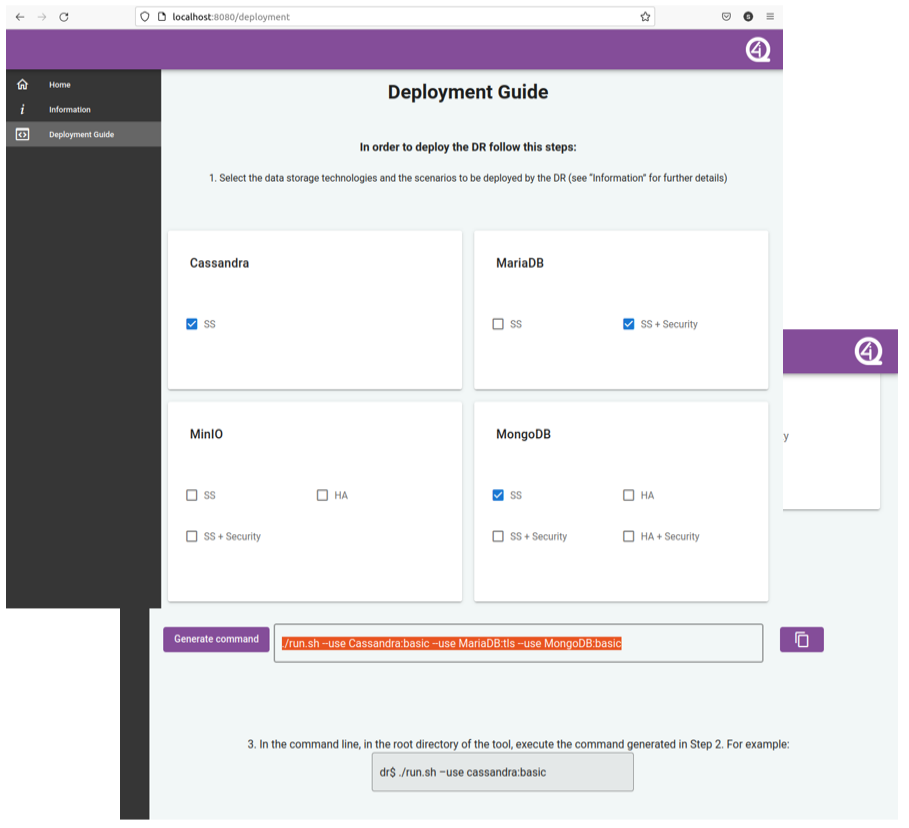
Screen “Deployment”, which shows the available scenarios for each one of the supported storage technologies, as displayed in the figure below. This screen allows the user to select the scenarios selected to be deployed by i4QDR and, according to such a selection, generated the exact command that must be executed in the shell in order to deploy the i4QDR.
GUI - Screen “Deployment”¶
In order to obtain the command to deploy the i4QDR the user must follow these steps:
Go to the “Deployment” screen
Choose the technologies and scenarios to be deployed by clicking on the corresponding checkboxes. For instance, select the “Single Server” scenario (“SS” checkbox) for Cassandra, and the “Single Server with Security” scenario (“SS+Security” checkbox) for MariaDB.
Click on the “Generate command” button. For the scenarios selected in the previous step, the generated command will be:
./run.sh --use cassandra:basic mariadb:tls
Click on the “Copy” button to copy the command shown in the textbox.
Open a console and cd into the solution’s main directory.
Paste the command copied on step 4 in the console and run it.
Deployment of i4QDR from the console¶
This section explains how to use the launcher script “run.sh” and provides specific information regarding the different parameters and options accepted by this script.
To learn about how to use the script, do this:
$ ./run.sh --help
To get a list of the available scenarios, do this:
$ ./run.sh --list
The correspondence between the scenarios described above and the naming used in the launcher script is as follows:
The “Single Server” scenario is denoted as “basic”.
The “Single Server with Security” scenario is denoted as “tls”.
The “High Availability” scenario is denoted as “repl”.
The “High Availability with Security” scenario is denoted as “repltls”.
To start a number of scenarios and an instance of Trino, use the –use parameter, as in the following example:
$ ./run.sh --use cassandra:basic --use mongodb:repl --use mysql:tls
To get debug information, use the –debug parameter, as in the following example:
$ ./run.sh --debug --use cassandra:basic
To do a dry run (simulate), use the –dry-run parameter, as in the following example:
$ ./run.sh --dry-run --use cassandra:basic
A dry run skips a number of actions including:
The creation of the Docker Compose .yaml file for Trino
The creation of a backup of the previous Docker Compose .yaml file for Trino
The start of the scenarios
The start of Trino
The –dry-run parameter can be combined with –debug, as in the following example:
$ ./run.sh --dry-run --debug --use cassandra:basic
In this case, a regular dry run is performed and the Docker Compose .yaml file is prepared and printed to stdout (but it is not written to a file).
Note that if the –list parameter is used, any –use is ignored. For instance, the following call is valid, but the –use parameters are ignored:
$ ./run.sh --list --use mongodb:basic --use mysql:tls
Manual bootstrapping of toolkits’ scenarios (without deploying Trino)¶
This section provides general information on how to bootstrap and use the different toolkits. The general way to use a toolkit consists in bootstrapping one of the scenarios it offers. For instance, to bootstrap the basic scenario for the mongodb toolkit, do this:
$ cd mongodb/
$ ./scenario_basic.sh
The result of bootstrapping an scenario is usually a number of Docker containers started and running and one or more server or services made available. For instance, after starting the basic scenario for the mongodb toolkit, there is an i4q_basic_mongo_1 container running, that hosts a regular MongoDB server.
Then, a number of actions can be performed on the scenario to manage the containers in different ways. To perform them, it is necessary to first load the script that implements the toolkit.
Other resources¶
Video demonstration (month M18): Link (private repository)
Deliverable “D3.16 - i4Q Data Repository v2” provides a technical description of the i4QDR solution, and explains implementation.
Resource
Location
Last document release (v.2.0.0)
Deliverable “D3.15 – Guidelines for building Data Repositories for Industry 4.0 v2” presents an overview of the role and importance of data repositories in Industry 4.0 contexts, such as this project. Furhtermore, this deliverable explains the challenges and requirements arising when developing data repositories and provides some recommendations on how to address them, using the i4QDR as an illustrative example.
Resource
Location
Last document release (v.2.0.0)