i4Q Data Integration and Transformation Services¶
General Description¶
i4QDIT is a distributed server-based platform with pre-processing and fusion services, able to prepare manufacturing data for being efficiently processed by microservice applications. i4QDIT includes all the elements required for manufacturing data stream management: reading, cleaning, filtering, feature extraction and fusion of different data sources.
i4QDIT is the solution responsible for the import and preparation of incoming data, mainly produced by sensors. i4QDIT will draw data from databases and/or directly from sensors, apply pre-processing functions from cleaning data to extracting features, and deliver a dataset suitable for analysis to other solutions. Besides preprocessing, i4QDIT will be responsible for the fusion of heterogeneous data and for the synchronization and alignment of different datasets.
Dealing with sensor streams, the inconsistencies among different sensors maybe many. From different timestamps to different sampling frequencies, sensor readings that may measure the same ‘problem’ usually require a lot of preparation in order to create a unified dataset.
Main Features¶
GUI. The solution shares a common UI with the other two solutions developed by CERTH (i4QIM and i4QQD). Through this UI the user can load a dataset, apply a set of pre-processing functions suitable for this pilot and visualize graphs of filtered vs unfiltered signals.
Data import. i4QDIT Solution can import data from storage solutions (i4QDR) or directly from the machines.
Data cleaning and preparation. This feature includes cleaning of wrong or duplicated values, computation of new variables, removal of outliers among others.
Pre-processing and feature extraction. i4QDIT Solution has developed customized pre-processing techniques according to the pilot use case. Some indicative examples are Fast Fourier Transformation, Empirical Mode Decomposition, etc.
Target audience¶
The i4QDIT Solution delivers data suitable for further analysis by importing data, applying pre-processing and feature extraction, as well as data cleaning. The solution can be used by analysts and engineers that want to perform filtering and extract features from raw signals. For this reason, some technical knowledge is required to better comprehend the functionalities of the solution.
Comercial information¶
Authors¶
Partner |
Role |
Website |
Logo |
|---|---|---|---|
CERTH |
Leader |

|
|
IKER |
Vice-Leader |

|
|
UNI |
Participant |

|
|
KBZ |
Participant |

|
|
ENG |
Participant |

|
Technical Specifications¶
The processes and services that are being included in the i4QDIT solution are mapped to two tiers in the i4Q Reference Architecture, Platform and Edge Tier.
Platform Tier: “Data Transformation” is one of the most important services of this solution, as it is responsible for transforming the data (usually post-processing) for each individual need for the microservices that require them. The main benefit of this service is that it can obtain and use data from repositories, already stored and ready to be transformed to a usable form. This gives the ability to use this solution without the need for newly acquired data. “Data Transformation” is the principle of this solution and will work both with data from repositories and in real-time. Any disruption of data will not allow this service to work properly.
Edge Tier: i4QDIT is the main solution responsible for the transformation and integration of data. Such operation requires services such as “Data Collecting”, “Data Management”, “Data Services” and “Distributed Computing”. “Distributed Computing” provides a model in which components of the software tool are shared among multiple computers(nodes) that allow deploying and running AI workloads on the edge. The benefit of this service is that the solution can be used on the manufacturing floor. “Data Collecting”, “Data Management” and “Data Services” can all be considered part of a pipeline, from data ingestion (collecting raw data from the facilities and storing them to make them available for pre-processing), to data management and transformation (pre-processing the data so that they can be fit to be used by other solutions). The use of these services is crucial for the proper development and operation of this solution. “Data Collecting”, “Data Management”, “Data Services” and “Distributed Computing” will mostly use real-time data. For these services to work seamlessly is important to establish an uninterrupted flow of sensor data from the shop floor.
Technical Development¶
This i4Q Solution has the following development requirements:
Development Language: Python >= 3.8
Containerization: Docker, Docker Compose
Deployment/Orchestration: -
User Interface: Streamlit
Database engine: i4QDR - MongoDB
Python libraries: Numpy, Pandas, SciPy, JSON, Matplotlib, PyEEMD
License¶
The licence is per subscription of 150€ per month.
Pricing¶
Subject |
Value |
|---|---|
Installation |
110€ (4-8 hours) |
Customisation |
3000€ (approx. 100 hours, depending on the client’s data format, annotated data availability) |
Training |
220€ (8-16 hours) |
Associated i4Q Solutions¶
Required¶
Can operate without the need for another i4Q solution
Not strict dependencies.
Optional¶
System Requirements¶
Docker requirements:
4 GB Ram
10 GB Storage (at least 5 GB for the Docker container)
64-bit operating system
Hardware virtualisation support
Installation Guidelines¶
Resource |
Location |
|---|---|
First release (v1.0.0) |
|
Second release (v2.0.0) |
|
Final Version (FIDIA) |
Installation¶
Decompress the contents of the zip file in a directory.
Include the necessary SSL certificates in the
Certificates/clientfolder to establish a secure connection to the Message Broker (these certificates are generated during the installation of the Message Broker). The required certificates are:
Certificate Authority (PEM file).
Client SSL certificate (PEM file).
Private SSL key (PEM file).
Open a command terminal.
Navigate to the directory where the artefacts have been decompressed from the zip file and locate the solution’s Docker compose file.
Execute the following command to build and run the containers defined in the file.
docker compose up -d
Open a web browser (preferably Google Chrome) and open the URL http://localhost:8501 to access the solution’s web interface.
User Manual¶
Most of the operations of the i4QDIT Solution are automated, as its purpose is to prepare in real-time the manufacturing data that is used in the subsequent analysis performed by the other i4Q Solutions for each pilot. In order to illustrate the new interactive functionalities implemented in the solution, a series of images of the graphical interface designed for this solution in the FIDIA pilot are shown below.
Explanation |
Image |
|---|---|
Data source selection The user can load data from different data sources: - Real-time data. The user can enter real manufacturing data into the platform using the API provided by FIDIA, specifying the IP address, port, and machine id. The data is then processed in the background and sent through the Message Broker using the DTI_topic_1 topic. - Local CSV files. The user can upload a CSV file with the data to be processed. - Preloaded data samples. Allows the user to test the solution with a set of data already uploaded by the user. - MongoDB. Allows the user to import data from a MongoDB database and data collection managed by the i4QDR Solution |

|
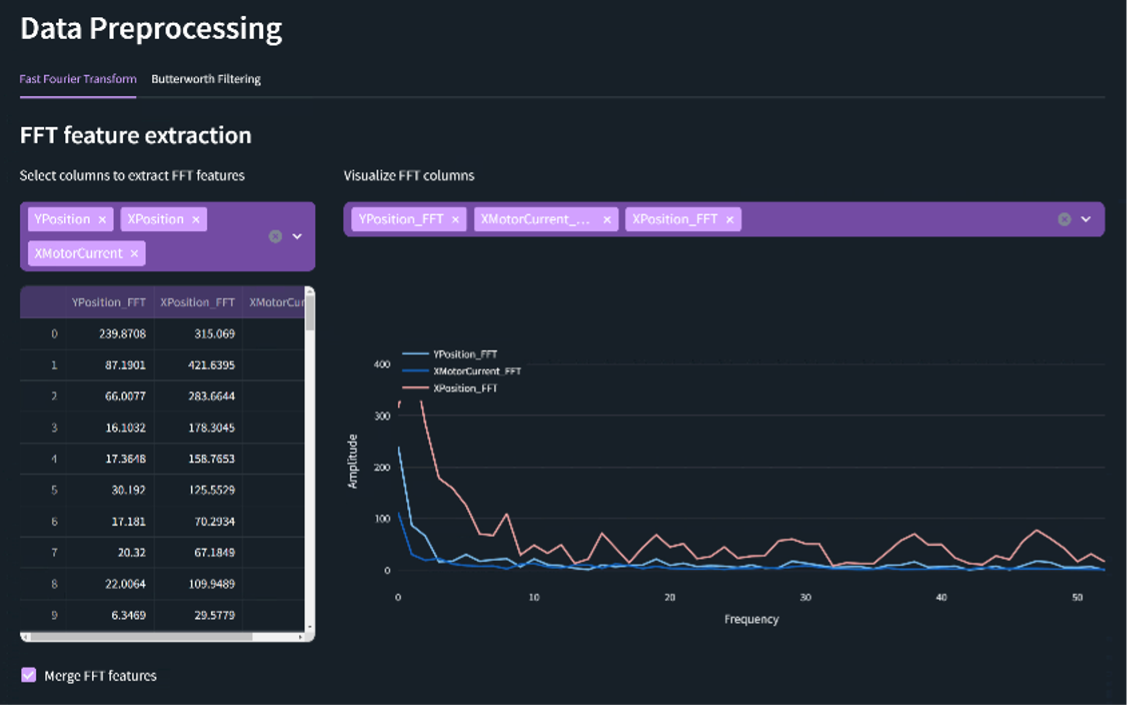
Data preprocessing Selecting a different data source, the user can load static data and apply a set of pre-processing techniques to enrich them. By choosing some of the sensors, it is possible to extract new information through FFT and Butterworth filtering and finally merge the new features into the original dataset. The newly extracted sensor features are also being presented via line-charts. |
|
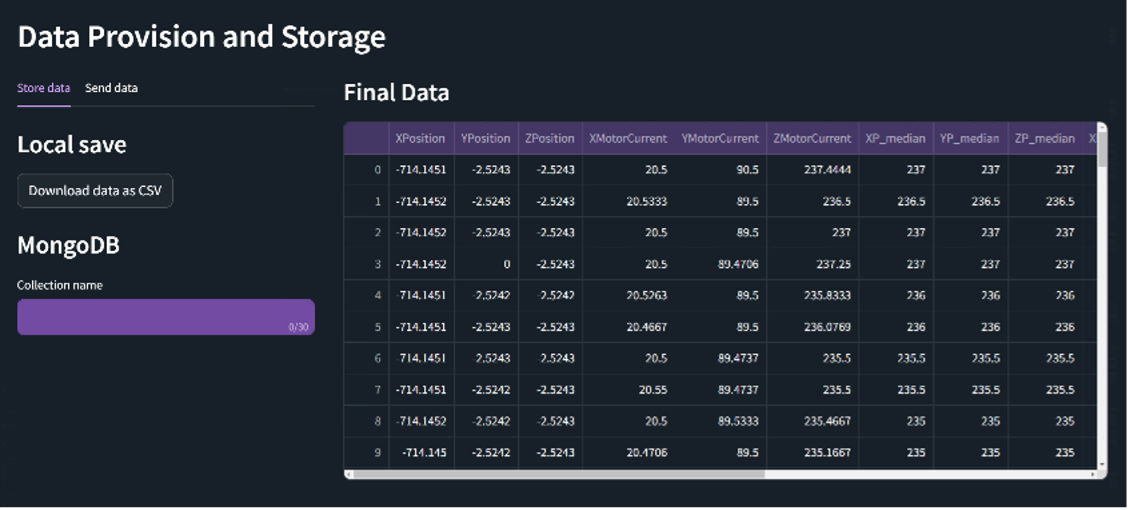
Data provision and storage Finally, the user has the options of downloading the final prepared dataset in a CSV format, save it in a MongoDB data collection provided by the i4QDR Solution or send it via the Message Broker. |
|